


資料來源:火山引擎 - 開發者社區
分布式 KVCache 的興起
背景
在大模型領域,隨著模型參數規模的擴大和上下文長度增加,算力消耗顯著增長。在 LLM
推理過程中,如何減少算力消耗并提升推理吞吐已經成為關鍵性優化方向。以多輪對話場景為例,隨著對話輪數增加,歷史 token
重算占比持續增長。實驗數據表明(如圖 1),當每輪輸入為 8k tokens 時,運行 6 輪后,歷史 token 重復計算占比超過
80%,直接導致了 GPU 算力的冗余消耗。在此背景下,構建高效的歷史 token
計算結果緩存機制,理論上可以實現對重復計算過程的智能規避,從而顯著提升計算資源的利用效率。
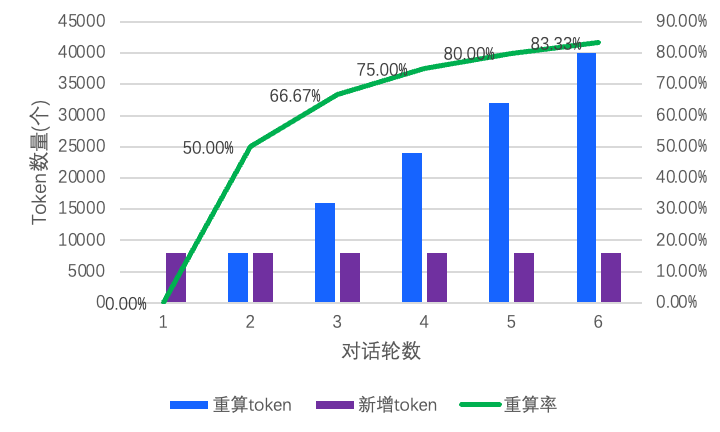
圖 1 對話輪數及重算率的變化
在應對上述技術挑戰中,KVCache 技術應運而生。
作為現代推理框架的核心組件,KVCache 能顯著優化系統性能。 以 vLLM 為例,其通過 Prefix Cache 和
PageAttention 技術,構建了基于本地 HBM 的 Local KVCache 方案。該方案中,緩存重用率(Cache
可被重復使用的比例)作為核心指標,通常認為與緩存容量呈正相關關系,即空間越大重用率越高,然而 Local KVCache
受限于本地存儲空間,容易遇到瓶頸。
從實驗數據看出(如圖 2),在 H20 硬件平臺運行 LLaMA-70B 模型時,每處理 1K
token 需要 1.6GB 空間,導致 Prefill 在 20 分鐘內即突破內存閾值。這一內存墻問題會引發 KVCache
頻繁驅逐舊數據,導致重用率下降,進而嚴重影響 KVCache 記憶長度,最終導致大量 token 重計算。為驗證內存墻問題的影響,我們在
LLaMA-70B 模型的長文本場景測試中發現(如圖 3),隨著文檔規模的增長,系統會快速觸及單機內存上限,導致 token 吞吐量驟降
70%,迫使系統陷入算力重復消耗的惡性循環。
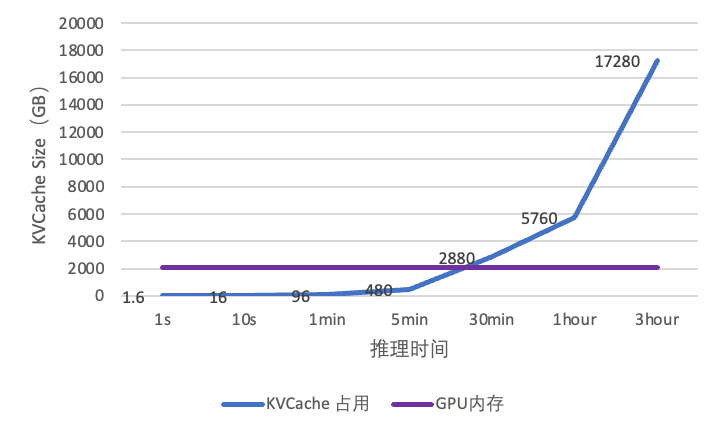
圖 2 KVCache 內存占用
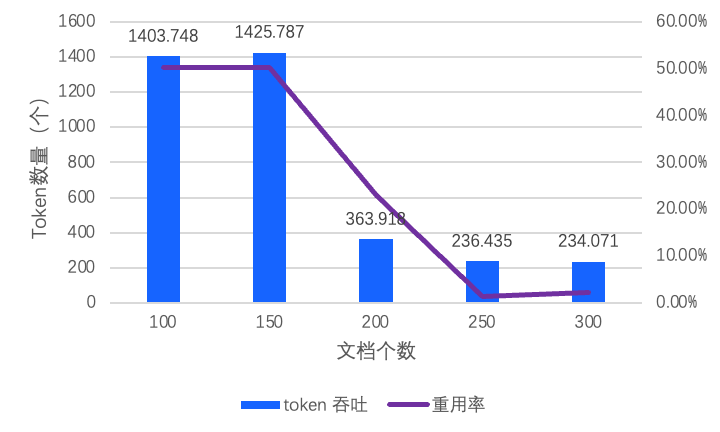
圖 3 Token 吞吐和 KVCache 重用率
Local KVCache 另一個關鍵局限于在于無法多機共享,主要影響以下典型場景:
- 多輪對話調度:多級推理通常需要通過復雜的調度來提升緩存重用率,如多輪對話中,同一會話需要盡可能調度至固定 GPU 以復用緩存,容易引發調度熱點與負載不均衡問題,實際場景中難以實現性能與資源利用率的平衡。
- PD 分離架構:系統將 Prefilling 和 Decoding 兩階段分離部署,需要通過高速網絡直接傳輸 KVCache。這不僅要求 PD 節點間網絡需要具備高吞吐能力以保證傳輸效率,還需避免傳輸過程中因調度問題觸發緩存失敗而引發重計算。同時,PD 分離中 Decoding 階段 KVCache 也難以被之后的推理復用,導致 GPU 算力空耗。
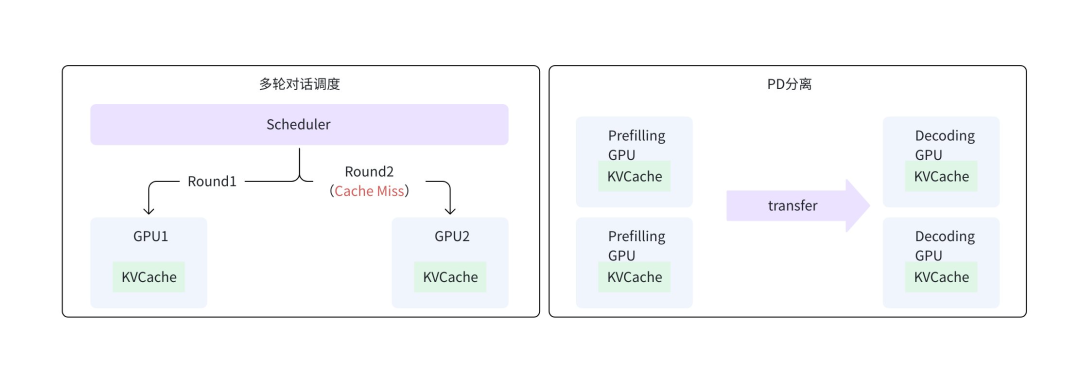
圖 4 KVCache 不能共享的場景
需求
基于上述分析,我們構建了一個彈性高性能的分布式 KVCache 服務,來優化 Local KVCache 方案的內存墻和不能共享的問題。區別于傳統分布式服務,分布式 KVCache 要求更高,對存儲的核心挑戰與需求如下:
- 更大的容量:構建分布式服務的初衷是為了解決傳統方案內存墻問題,需具備海量容量用以支撐大規模推理的高命中率需要。
- 更低的訪問時延:HBM 到分布式緩存之間存在網絡開銷,開銷太大會影響 GPU 執行效率,提升 HBM 及分布式 Cache 之間的交換效率至關重要。
- 更高的吞吐:KVCache 通過多機間共享提升重用率,這是分布式 KVCache 的優勢,然而隨之而來的,需要 KVCache 服務提供更加極致的吞吐以支撐大規模推理服務部署。
火山引擎推理 KVCache 解決方案
彈性極速緩存 EIC
彈性極速緩存 EIC(Elastic Instant Cache)是火山引擎存儲團隊面向大語言模型推理場景推出的高性能分布式 KVCache
緩存服務。隨著互聯網技術的演進與流量規模的激增,緩存技術逐漸成為系統架構的核心組件,火山引擎存儲團隊基于自身業務內部加速需求自主研發了
EIC,歷經 4 年技術沉淀,該系統已支撐了公司內部存儲、推理、廣告推薦等大規模業務場景。
EIC KVCache 支持將內存和 SSD
組成一個分布式服務,構建多層緩存體系,實現顯存容量的靈活擴展與計算資源的高效解耦。還支持和 GPU 混合部署,將 GPU
剩余顯存、內存和磁盤統一池化管理,在提升計算效率的同時顯著擴展上下文長度,成為加速推理框架的核心鏈路。基于通用模型和推理引擎,無縫兼容主流大語言模型架構,達成單客戶端百
GB 級 KVCache 吞吐與亞毫秒級響應,滿足高并發、低延遲的生成式 AI 場景需求。
EIC 核心特性
緩存池化:多級緩存、數據流動
EIC 通過整合 GPU 集群閑置內存和磁盤,構建分布式緩存池,突破單機內存墻限制。分布式內存池化的核心目標是基于統一的多級存儲資源池化管理(GPU 顯存、CPU 內存、SSD 及其他緩存系統),實現顯存容量的靈活擴展與計算資源的高效解耦。
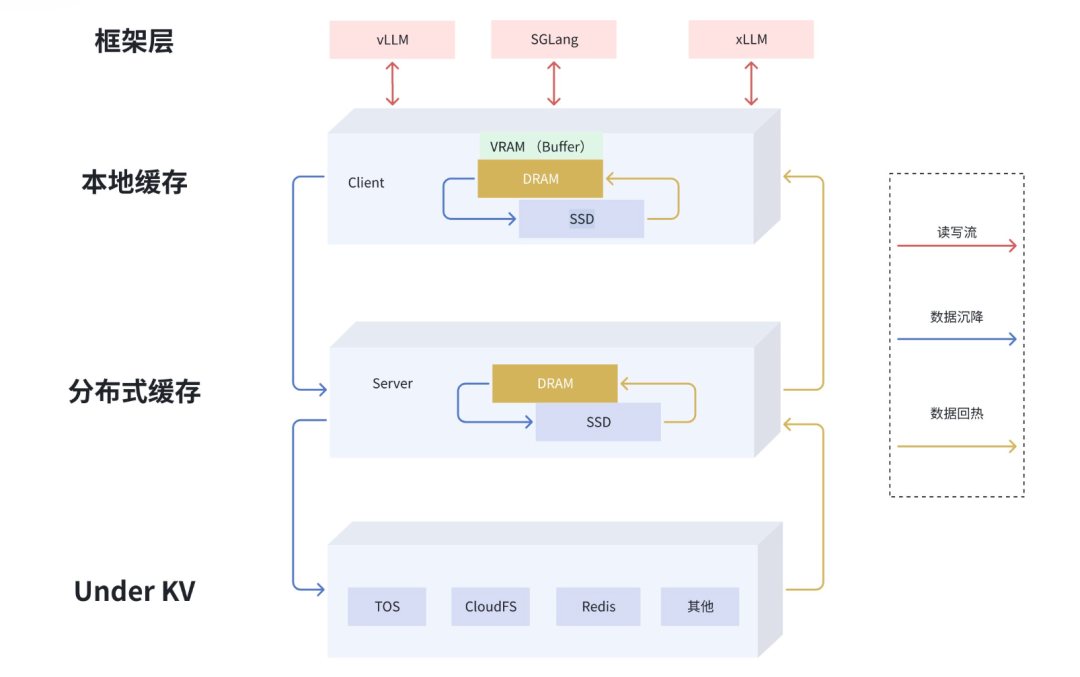
圖 5 多級透明緩存
推理緩存 KVCache Offload 至分布式緩存后,具備以下優勢:
- 去中心架構:采用去中心化 DHT 架構,實現數據與元數據面解耦,支撐高性能讀寫,支持在線擴縮容和數據遷移。
- 超大容量:支持靈活 Scale-out,通過云原生平臺快速納管 GPU 節點空閑資源,構建 10PB 級存儲池,緩存命中率提升 10 倍以上。
- 多級緩存:兼顧容量與性能,支持 GPU - 本地緩存 - 分布式緩存 (RAM+SSD) 等多層級緩存系統,基于不同存儲介質特性,構建大容量緩存池,并且支持緩存在各層級間高效流動,實現性能的最大化。
- 數據流動:支持緩存在不同層級間的流動,可基于用戶需求,將冷數據下沉到低速存儲,將熱數據上升到高速緩存,支持包括基于時間的 TTL 策略、基于空間的 LRU/ARC/FIFO 等策略。
- 內存持久化:支持進程故障和在線熱升級,寫入內存緩存不丟失,支持毫秒級快速恢復,同時內存引擎支持 Hugepage、Numa Aware、全鏈路零拷貝、JumboFrame 等新特性。
- 熱點均衡:支持熱點緩存識別,同時支持熱點緩存進行副本自動擴展和生命周期管理,通過多副本負載均衡,避免少量熱點緩存和節點成為系統瓶頸,確保了熱點場景的服務穩定性。
低時延:GPU Direct RDMA
- GPU Direct:GPU Direct 是 NVIDIA 開發的一項技術,可實現 GPU 與其他設備(例如網絡接口卡 GPU Direct RDMA 和存儲設備 GPU Direct Storage)之間繞過 CPU 的直接通信和數據傳輸。該技術允許 GPU 直接訪問 RDMA 網絡設備中的數據,無需通過主機內存或 CPU 的中介,能夠顯著減少傳輸時延提高傳輸帶寬,尤其適用于高吞吐、低延遲的 AI 推理場景。
- 多協議兼容性:EIC 支持內核態 TCP、用戶態 TCP、RDMA 及 GPU Direct RDMA 訪問,適配各種硬件環境。
- 網絡極致優化:在高帶寬和推理 IO 突發場景下,通過深度優化投遞模型、線程模型、網絡傳輸等,大幅降低了網絡傳輸(包括突發場景)長尾時延,從而提升推理體驗。
GDR 可以實現全鏈路內存零拷貝,支持極低的訪問時延。在不同 IO 大小的測試中,GDR 的表現良好(圖 7),時延可以達到 TCP 或 RDMA 的十分之一。
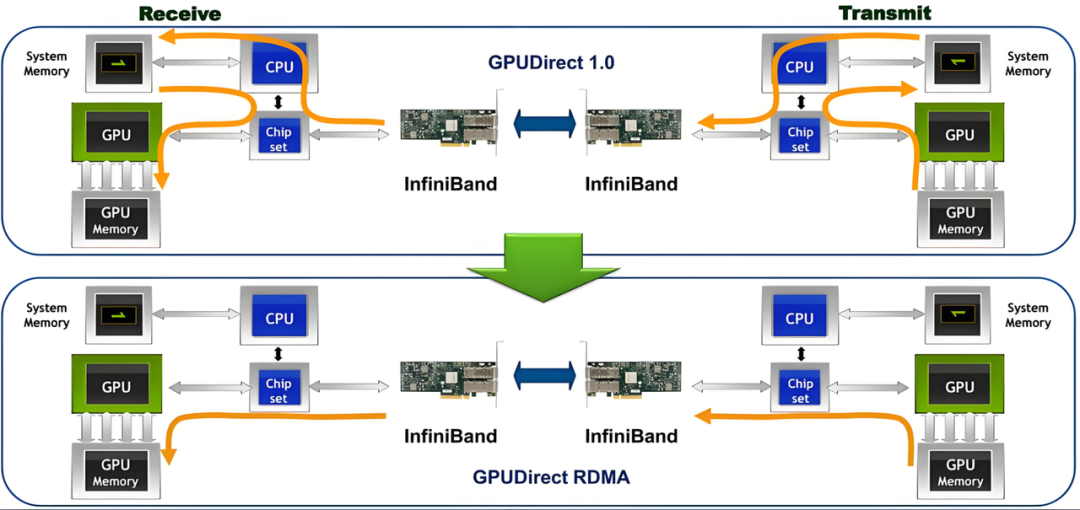
圖 6 GDR 工作示意圖
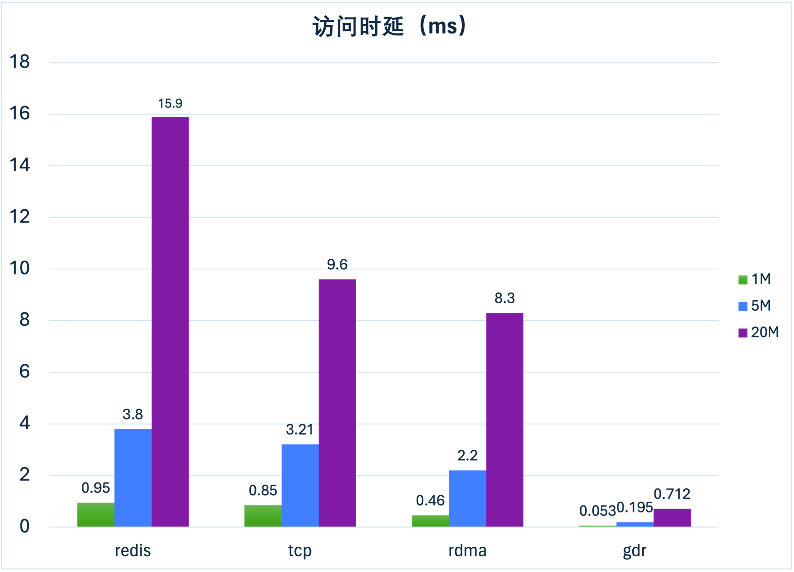
圖 7 GDR 性能對比
EIC 與 Local KVCache 在實際推理場景中的效果對比如下:
- 推理場景:使用兩臺 H20 部署 SGLang + Deepseek R1 做推理,設置 TTFT SLO 5 秒、8K Input 200 output 測試多輪對話。
- 實測數據對比:
- 吞吐提升:首輪無 KVCache 復用階段,性能基本持平;次輪起 EIC 吞吐從 1.5K 增長至 5.5K,實現 3 倍以上性能提升(圖 8)。
- 時延優化:首輪無 KVCache 復用階段,性能基本持平;次輪起時延降至 1 秒,降幅達 67%。
- 結論:得益于 EIC 低時延和大容量帶來的緩存高復用,同等算力條件下,推理吞吐性能可提升 3 倍以上;若維持原有性能指標,算力需求可大幅縮減,實現性能與成本的雙重優化。
圖 8 EIC KVCache 推理框架以存代算性能對比
高吞吐:多網卡、拓撲親和、模型高速加載
模型分發場景中,推理冷啟動對模型加載的速度要求較高,模型加載的速度決定了推理服務的彈性能力。隨著模型的增長,傳統存儲服務的加載速度逐漸緩慢。EIC
通過分布式緩存,實現模型文件到推理框架的高速加載,顯著提升推理服務彈性。我們對比了模型在 H20 機型上從 NVMe SSD
(傳統存儲服務的性能基線) 和 從 EIC 的加載速度,測試數據顯示(圖 9):
- DeepSeek-R1(642GB):模型文件 IO 加載時間從 NVMe SSD 的 546 秒降至 13 秒,效率提升 42 倍。
- DeepSeek-R1-Distill-Llama-70B (131GB):模型文件 IO 加載時間從 84 秒壓縮至 5 秒,加載速度提升 16 倍,加速效果十分顯著。
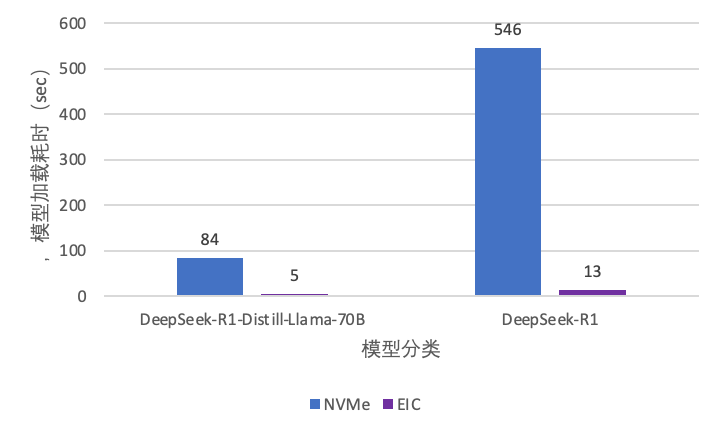
圖 9 EIC KVCache 推理框架模型加載性能對比
為應對大模型高并發場景的 KVCache 吞吐需求,EIC 通過多網卡并行傳輸和負載均衡技術,大幅提升了系統性能上限;同時為了解決不同 GPU
間訪問網卡的時延差異,EIC 支持感知 GPU 和網卡拓撲結構,基于親和性來選擇最優網卡傳輸數據,達到時延和吞吐的極致優化(如圖
10)。GPU 機型的 Root Complex 是 Socket 級別,可轉化為 NUMA 級別親和,比如 Mem0 利用 R0 網卡和 R1
網卡發送延遲更低,GPU0 利用 R0 網卡發送延遲更低,我們測試多種配置場景,依賴多網卡、拓撲親和等特性,單機可以輕松突破 100GB/s
帶寬(圖 11)。
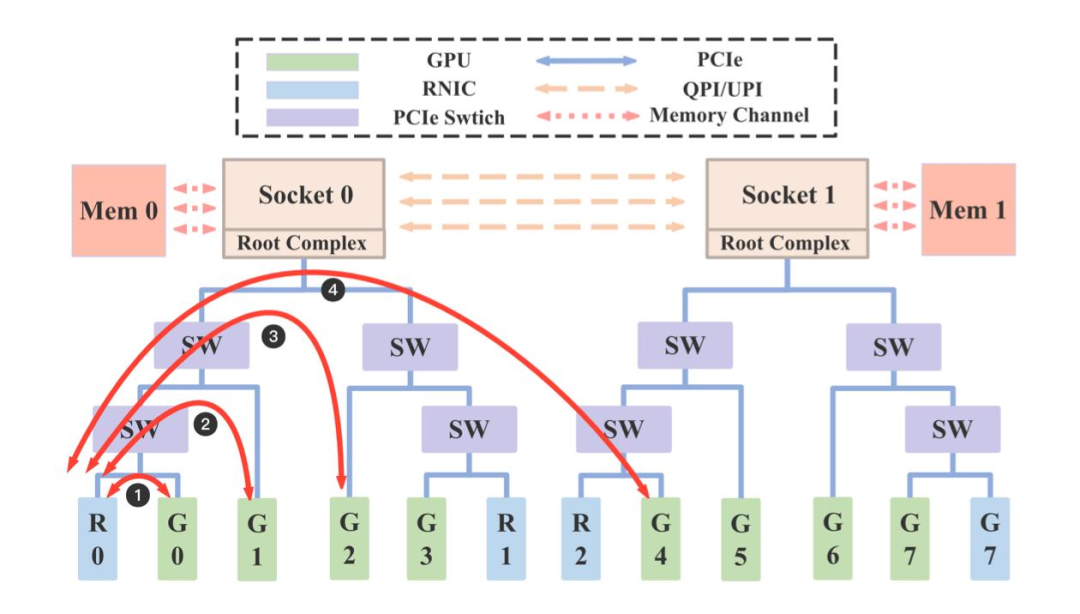
圖 10 GPU 網絡親和示意圖
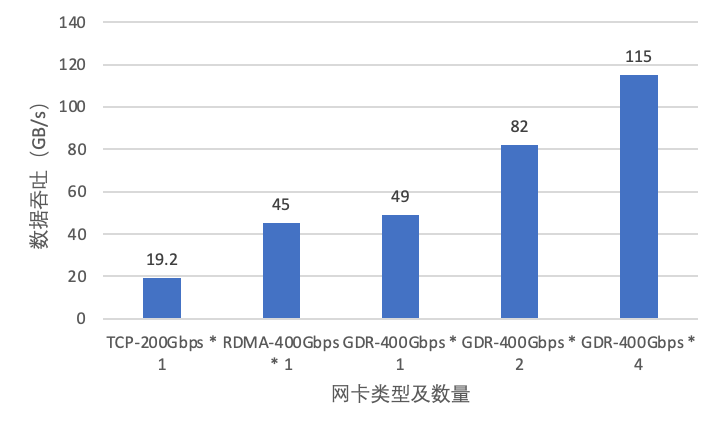
圖 11 EIC 讀帶寬性能測試
高易用:Namespace 切分
EIC 支持多 Namespace 能力,可以實現數據分類,圍繞 Namespace 支持以下特性:
- 適配多種介質:支持為 Namespace 設置不同存儲介質,如內存、SSD 或組合模式,滿足不同場景對容量和性能的需求。
- 數據流動策略:當選擇內存 + SSD 混合模式時,支持選擇不同數據流動和驅逐策略,如 TTL、LRU、LFU、ARC 等。
- 空間配額:支持為單個 Namespace 設置空間大小,避免跨 Namespace 空間搶占。
- QoS 策略:支持為單個 Namespace 設置不同的 IOPS 和帶寬,避免跨 Namespace 吞吐搶占。
- 可觀測性:基于 Namespace 監控吞吐 / 時延 / 命中率 / 緩存數量 / 緩存容量等,方便用戶細粒度觀察系統。
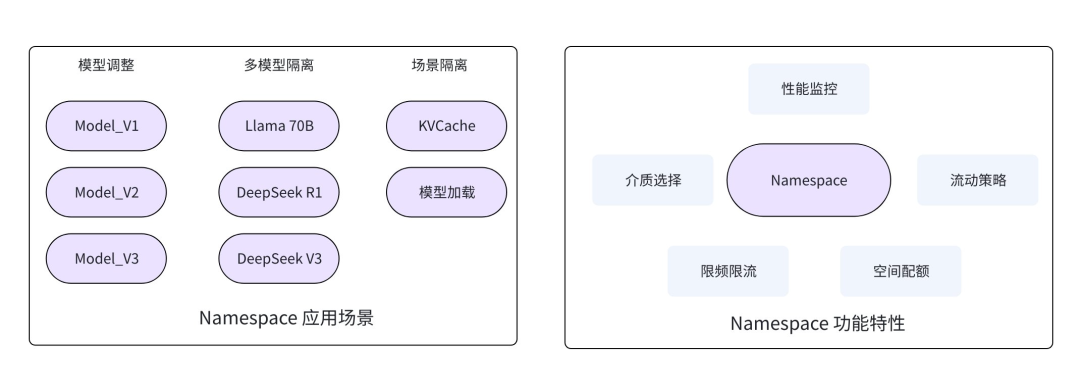
圖 12 Namespace 特性及應用場景
在 LLM 場景中,Namespace 能力有以下應用,滿足實際場景需求:
- 模型隔離:基于模型類型隔離,簡化代碼接入流程,支持不同模型的精細化調優。
- 模型調整:通過模型版本號的方式設置 Namespace,實現新模型無縫切換部署,舊版本 KVCache 自動失效并快速釋放緩存資源。
- 場景隔離:在大規模模型冷啟動場景中,系統對吞吐帶寬的需求極高,且與模型規模呈正相關關系。在此場景下,模型加載過程可能會搶占 KVCache 的帶寬資源。此時可將兩種數據通過 Namespace 隔離劃分,并針對模型加載對應的 Namespace 配置限流策略和優先級隊列,實現相對公平的 WFQ (加權公平排隊,Weighted Fair Queuing),保障 KVCache 服務穩定性。
生態兼容:AI 云原生和開源生態集成
EIC 支持用戶利用其 GPU 服務器的空閑內存和 SSD 資源,構建半托管或者全托管的高性能緩存池,目前, EIC
管控服務基于火山引擎托管,既能夠依托火山引擎的 VKE 構建服務,也可基于開源的 K8S 構建服務。我們積極融入開源生態,已完成對
vLLM、SGLang 以及 Dynamo 等推理框架的適配,并將其集成至火山引擎 AI 相關重要業務中。
開源生態集成
我們基于 vLLM、SGLang 與 Dynamo 的開源實現,開發了 KV Transfer 緩存共享(Cache Reuse and
Sharing)技術。該技術已成功在 PD 分離和模型并行架構下實現高效共享。與傳統方案相比,在長文本場景中,推理吞吐提升 3 倍,首次
token 生成時間(TTFT)降低 67%。同時,我們優化了模型加載鏈路,支持模型通過多網卡從 EIC 進行高速直傳,以
DeepSeek-R1(642GB)模型為例,其加載時間可縮減至 13 秒,顯著提升模型部署效率。目前,我們已完成 EIC
集成的預制鏡像制作,并計劃將其貢獻至開源社區,與社區開發者共同打造更高效、靈活的推理解決方案。
云原生開箱即用
在 EIC
集成方面,我們提供的預制鏡像與白屏化集群管理平臺深度協同,用戶僅需在集群管理頁面一鍵操作,即可將 VKE 和自建 K8S 推理集群集成 EIC
服務,并自動生成適配 SGLang、vLLM 和 Dynamo 的 Helm Chart
包。借助該工具,推理框架的部署流程得到大幅簡化,真正實現一鍵式快速啟動。我們編制了詳盡的最佳實踐文檔,圍繞
VKE(容器服務)/Kubernetes Yaml 及 Helm
兩種主流部署方式,完整展示從環境配置、參數優化到服務上線的全流程操作指南,幫助用戶快速掌握高效部署方法,降低技術門檻,加速 EIC
與推理框架的深度融合應用。
展望
未來 EIC 將繼續從以下維度持續演進,進一步提升產品能力和用戶體驗,敬請期待:
- 特性層面:深度結合大模型,支持推理算子下推、Sparse Attention,提供更易用的 AI 數據類型和接口,實現更加智能的數據流動,貼近開發者優化開箱即用等,提供更貼近 AI 云原生的使用方式和服務體驗。
- 性能層面:隨網絡極限(200/400/800Gb)拓展 EIC 的單機極限上限,確保接近網絡極限時始終保持高吞吐和低延遲穩定性;同時結合軟件 / 網絡多路徑,優化推理長尾時延。
- 緩存層面:進一步優化內存 / SSD 等緩存使用效率,同時結合大模型 IO 特性進行智能化壓縮,為用戶節省成本;持續整合 VRAM、DRAM、SSD、UnderKV 等異構介質和服務器,形成統一大緩存池并實現高效利用和管理。
- 生態層面:快速跟進大模型技術演進,與社區合作深度合作,推進與 vLLM/SGLang/Dynamo 等框架在 PD 分離、推理調度、緩存多機共享等特性上的共同演進與深度融合。
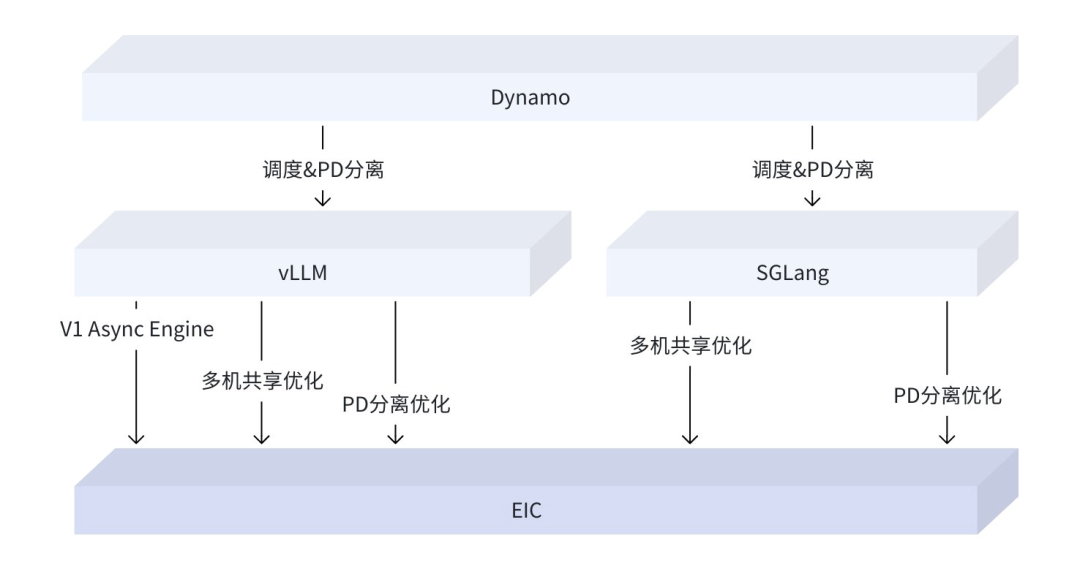
圖 13 推理框架與 EIC 生態演進